



RT-qPCR साधारण PCR प्रविधिबाट विकसित गरिएको हो।यसले परम्परागत PCR प्रतिक्रिया प्रणालीमा फ्लोरोसेन्ट रसायनहरू (फ्लोरोसेन्ट रङहरू वा फ्लोरोसेन्ट प्रोबहरू) थप्छ, र तिनीहरूको विभिन्न ल्युमिनेसेन्ट मेकानिजमहरू अनुसार वास्तविक समयमा PCR annealing र विस्तार प्रक्रिया पत्ता लगाउँदछ।PCR को प्रत्येक चक्रमा उत्पादन परिवर्तनको मात्रा गणना गर्न माध्यममा फ्लोरोसेन्ट संकेत परिवर्तनहरू प्रयोग गरिन्छ।हाल, सबैभन्दा सामान्य विधिहरू फ्लोरोसेन्ट डाई विधि र प्रोब विधि हुन्।
फ्लोरोसेन्ट डाई विधि:
केही फ्लोरोसेन्ट रंगहरू, जस्तै SYBR ग्रीन Ⅰ, PicoGreen, BEBO, आदि, आफैंले प्रकाश उत्सर्जन गर्दैन, तर dsDNA को माइनर ग्रूभमा बाँधिएपछि फ्लोरोसेन्स उत्सर्जन गर्दछ।त्यसैले, पीसीआर प्रतिक्रियाको सुरुमा, मेसिनले फ्लोरोसेन्ट संकेत पत्ता लगाउन सक्दैन।जब प्रतिक्रिया एनेलिङ-एक्सटेन्सन (दुई-चरण विधि) वा विस्तार चरण (तीन-चरण विधि) मा अगाडि बढ्छ, यस समयमा डबल स्ट्र्यान्डहरू खोलिन्छन्, र नयाँ DNA पोलिमरेज स्ट्र्यान्ड संश्लेषणको क्रममा, फ्लोरोसेन्ट अणुहरू dsDNA माइनर ग्रूभमा मिलाइन्छ र फ्लुरेन्स उत्सर्जन हुन्छ।PCR चक्रको संख्या बढ्दै जाँदा, dsDNA सँग अधिक र अधिक रंगहरू जोडिन्छन्, र फ्लोरोसेन्ट संकेत पनि निरन्तर बढाइन्छ।उदाहरणको रूपमा SYBR ग्रीन Ⅰ लिनुहोस्।
जाँच विधि:
ताकमान प्रोब सबैभन्दा बढी प्रयोग हुने हाइड्रोलिसिस प्रोब हो।त्यहाँ प्रोबको 5′ अन्त्यमा फ्लोरोसेन्ट समूह हुन्छ, सामान्यतया FAM।प्रोब आफैं लक्ष्य जीनको लागि पूरक अनुक्रम हो।फ्लोरोफोरको 3′ छेउमा फ्लोरोसेन्ट शमन समूह छ।फ्लोरोसेन्स अनुनाद ऊर्जा स्थानान्तरण (Förster रेजोनान्स ऊर्जा स्थानान्तरण, FRET) को सिद्धान्त अनुसार, जब रिपोर्टर फ्लोरोसेन्ट समूह (दाता फ्लोरोसेन्ट अणु) र क्वेन्चिंग फ्लोरोसेन्ट समूह (स्वीकारकर्ता फ्लोरोसेन्ट अणु) जब एक्साइटेशन स्पेक्ट्रम ओभरल्याप हुन्छ र दूरी धेरै नजिक हुन्छ (एक्सिटेशन 1 मा)। स्वीकारकर्ता अणु को प्रतिदीप्ति, जबकि autofluorescence कमजोर छ।तसर्थ, पीसीआर प्रतिक्रियाको सुरुमा, जब जाँच प्रणालीमा स्वतन्त्र र अक्षुण्ण हुन्छ, रिपोर्टर फ्लोरोसेन्ट समूहले प्रतिदीप्ति उत्सर्जन गर्दैन।एनिलिङ गर्दा, प्राइमर र प्रोब टेम्प्लेटमा बाँधिन्छ।विस्तार चरणको समयमा, पोलिमरेजले लगातार नयाँ चेनहरू संश्लेषण गर्दछ।DNA पोलिमरेजमा 5′-3′ exonuclease गतिविधि छ।प्रोबमा पुग्दा, डीएनए पोलिमरेजले टेम्प्लेटबाट प्रोबलाई हाइड्रोलाइज गर्नेछ, रिपोर्टर फ्लोरोसेन्ट समूहलाई क्वेन्चर फ्लोरोसेन्ट समूहबाट अलग गर्नेछ, र फ्लोरोसेन्ट संकेत जारी गर्नेछ।प्रोब र टेम्प्लेट बीच एक-देखि-एक सम्बन्ध भएको हुनाले, परीक्षणको शुद्धता र संवेदनशीलताको सन्दर्भमा जाँच विधि डाई विधि भन्दा उच्च छ।
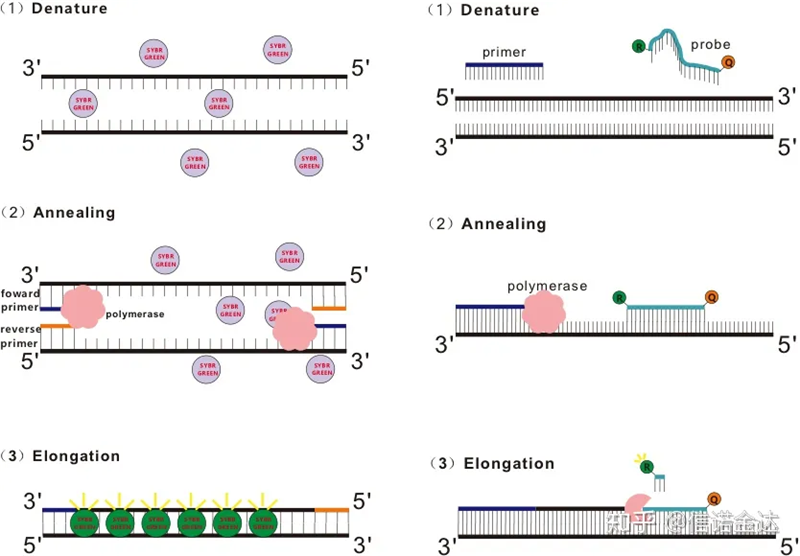
चित्र 1 qRT-PCR को सिद्धान्त
प्राइमर डिजाइन
सिद्धान्तहरू:
प्राइमरहरू न्यूक्लिक एसिड श्रृंखलाको संरक्षित क्षेत्रमा डिजाइन गरिनु पर्छ र विशिष्टता हुनुपर्छ।
यो cDNA अनुक्रम प्रयोग गर्न सबै भन्दा राम्रो छ, र mRNA अनुक्रम पनि स्वीकार्य छ।यदि होइन भने, DNA अनुक्रमको cds क्षेत्र डिजाइन पत्ता लगाउनुहोस्।
फ्लोरोसेन्ट परिमाणात्मक उत्पादनको लम्बाइ 80-150bp हो, सबैभन्दा लामो 300bp हो, प्राइमरको लम्बाइ सामान्यतया 17-25 आधारहरू बीचको हुन्छ, र अपस्ट्रिम र डाउनस्ट्रीम प्राइमरहरू बीचको भिन्नता धेरै ठूलो हुनु हुँदैन।
G+C सामग्री 40% र 60% को बीचमा छ, र 45-55% सबै भन्दा राम्रो छ।
TM मान ५८-६२ डिग्रीको बीचमा छ।
प्राइमर डाइमर र सेल्फ-डाइमरहरू बेवास्ता गर्ने प्रयास गर्नुहोस्, (लगातार पूरक आधारहरूको 4 जोडी भन्दा बढी नदेखाउनुहोस्) हेयरपिन संरचना, यदि अपरिहार्य छ भने, ΔG<4.5kJ/mol बनाउनुहोस्* यदि तपाईं उल्टो ट्रान्सक्रिप्सन सफा गर्दा gDNA हटाइएको छ भनी सुनिश्चित गर्न सक्नुहुन्न भने, इन्ट्रोनको प्राइमरहरू डिजाइन गर्नु उत्तम हुन्छ, GAT ′′ बाट बच्न र GAT ′ ′ मोडबाट टाढा हुन सक्दैन। /C, A/G निरन्तर संरचना (2-3) प्राइमर र गैर-
विशिष्ट विषमतापूर्वक एम्प्लीफाइड अनुक्रमको समरूपता 70% भन्दा कम वा 8 पूरक आधार होमोलोजी छ।
डाटाबेस:
CottonFGD कुञ्जी शब्दहरू द्वारा खोज
प्राइमर डिजाइन:
IDT-qPCR प्राइमर डिजाइन
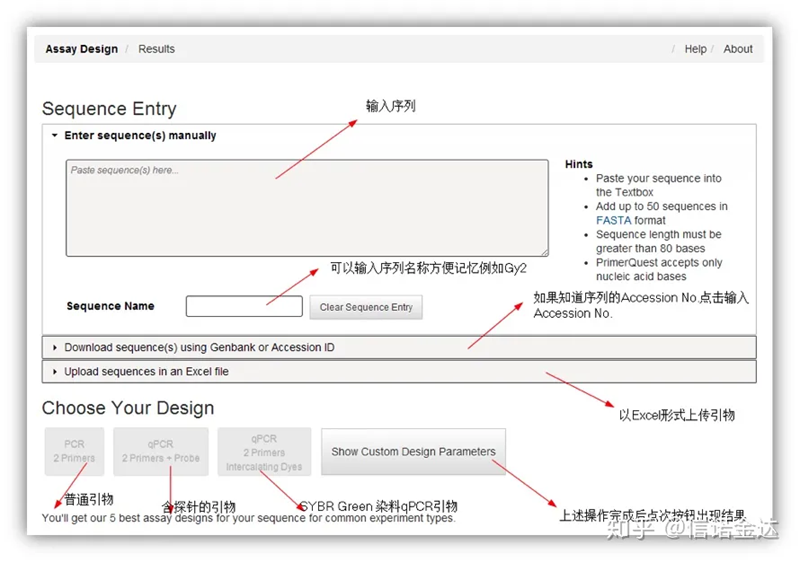
Fig2 IDT अनलाइन प्राइमर डिजाइन उपकरण पृष्ठ
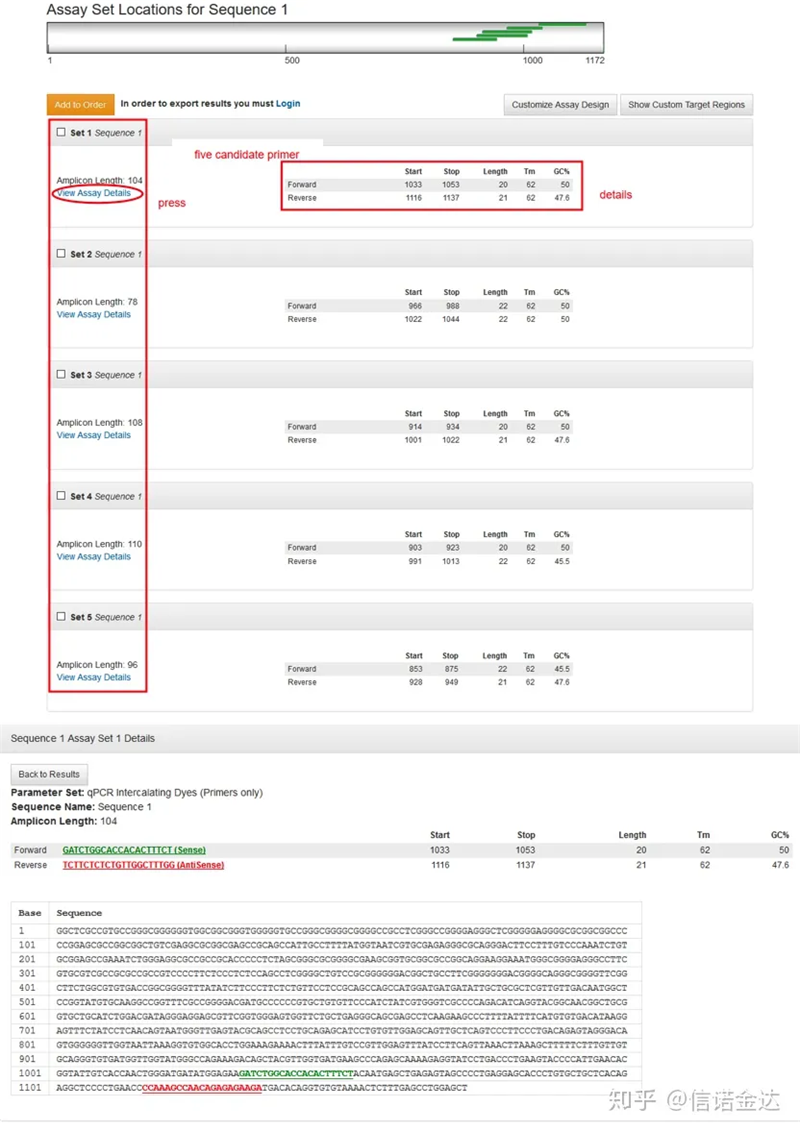
Fig3 परिणाम पृष्ठ प्रदर्शन
lncRNA प्राइमरको डिजाइन:
lncRNA:mRNA को समान चरणहरू।
miRNA:स्टेम-लूप विधिको सिद्धान्त: सबै miRNA हरू लगभग 23 nt को छोटो अनुक्रमहरू भएकाले, प्रत्यक्ष PCR पत्ता लगाउन सकिँदैन, त्यसैले स्टेम-लूप अनुक्रम उपकरण प्रयोग गरिन्छ।स्टेम-लूप अनुक्रम लगभग 50 nt को एकल-स्ट्र्यान्डेड DNA हो, जसले आफैंले हेयरपिन संरचना बनाउन सक्छ।3 'अन्तलाई miRNA आंशिक टुक्राको लागि पूरक अनुक्रमको रूपमा डिजाइन गर्न सकिन्छ, त्यसपछि लक्ष्य miRNA लाई रिभर्स ट्रान्सक्रिप्शनको क्रममा स्टेम-लूप अनुक्रममा जडान गर्न सकिन्छ, र कुल लम्बाइ 70bp पुग्न सक्छ, जुन qPCR द्वारा निर्धारित एम्प्लीफाइड उत्पादनको लम्बाइसँग मिल्दोजुल्दो छ।टेलिङ miRNA प्राइमर डिजाइन।
प्रवर्धन-विशिष्ट पत्ता लगाउने:
अनलाइन ब्लास्ट डाटाबेस: अनुक्रम समानता द्वारा CottonFGD विस्फोट
स्थानीय ब्लास्ट: स्थानीय ब्लास्ट गर्न ब्लास्ट+ प्रयोग गर्ने सन्दर्भ गर्नुहोस्, लिनक्स र म्याकोसले सीधै स्थानीय डाटाबेस स्थापना गर्न सक्छ, Win10 प्रणाली पनि ubuntu bash स्थापना पछि गर्न सकिन्छ।स्थानीय विस्फोट डाटाबेस र स्थानीय विस्फोट सिर्जना गर्नुहोस्;Win10 मा ubuntu bash खोल्नुहोस्।
नोटिस: अपल्याण्ड कपास र समुद्री टापु कपास टेट्राप्लोइड बालीहरू हुन्, त्यसैले विस्फोटको परिणाम प्रायः दुई वा बढी मिलान हुनेछ।विगतमा, विस्फोट गर्न डाटाबेसको रूपमा NAU cds प्रयोग गर्दा केही SNP भिन्नताहरू भएका दुई समरूपी जीनहरू फेला पार्न सकिन्छ।सामान्यतया, दुई समरूप जीनहरू प्राइमर डिजाइनद्वारा छुट्याउन सकिँदैन, त्यसैले तिनीहरूलाई समान रूपमा व्यवहार गरिन्छ।यदि त्यहाँ स्पष्ट इन्डेल छ भने, प्राइमर सामान्यतया इन्डेलमा डिजाइन गरिएको हुन्छ, तर यसले प्राइमरको माध्यमिक संरचनामा निम्त्याउन सक्छ मुक्त ऊर्जा उच्च हुन्छ, जसले प्रवर्द्धन दक्षतामा कमी ल्याउन सक्छ, तर यो अपरिहार्य छ।
प्राथमिक माध्यमिक संरचना को पहिचान:
चरणहरू:ओलिगो 7 → इनपुट टेम्प्लेट अनुक्रम खोल्नुहोस् → उप-विन्डो बन्द गर्नुहोस् → सेभ गर्नुहोस् → टेम्प्लेटमा प्राइमर पत्ता लगाउनुहोस्, प्राइमर लम्बाइ सेट गर्न ctrl+D थिच्नुहोस् → विभिन्न माध्यमिक संरचनाहरू विश्लेषण गर्नुहोस्, जस्तै सेल्फ-डाइमराइजेसन बडी, हेटरोडिमर, हेयरपिन, मिसम्याच, इत्यादि। परीक्षणका परिणामहरूका अन्तिम दुई चित्रहरू हुन्।अगाडिको प्राइमरको नतिजा राम्रो छ, त्यहाँ कुनै स्पष्ट डाइमर र हेयरपिन संरचना छैन, कुनै निरन्तर पूरक आधारहरू छैनन्, र मुक्त ऊर्जाको निरपेक्ष मूल्य 4.5 भन्दा कम छ, जबकि पछाडिको प्राइमरले निरन्तर देखाउँछ 6 आधारहरू पूरक छन्, र मुक्त ऊर्जा 8.8 छ;थप रूपमा, 3′ अन्त्यमा थप गम्भीर डाइमर देखिन्छ, र लगातार 4 आधारहरूको डाइमर देखिन्छ।यद्यपि मुक्त ऊर्जा उच्च छैन, 3′ dimer Chl ले प्रवर्धन विशिष्टता र प्रवर्धन दक्षतालाई गम्भीर रूपमा असर गर्न सक्छ।साथै, हेयरपिन, हेटरोडिमर र बेमेलको लागि जाँच गर्न आवश्यक छ।
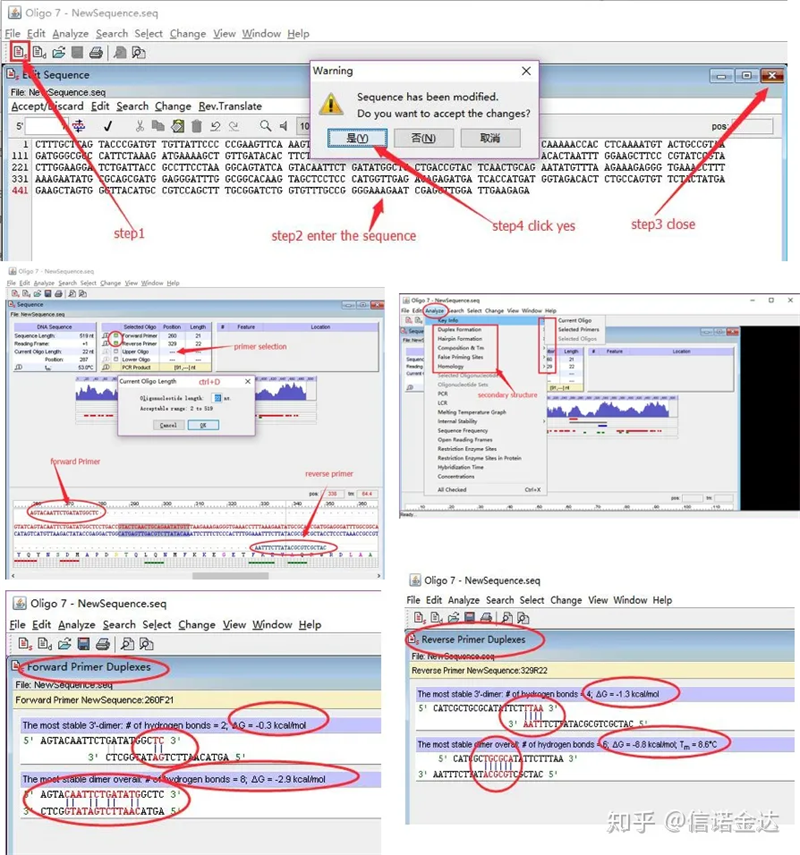
Fig3 oligo7 पत्ता लगाउने परिणामहरू
प्रवर्धन दक्षता पत्ता लगाउने:
PCR प्रतिक्रियाको प्रवर्धन दक्षताले PCR परिणामहरूलाई गम्भीर रूपमा असर गर्छ।साथै qRT-PCR मा, एम्प्लीफिकेशन दक्षता मात्रात्मक परिणामहरूको लागि विशेष रूपमा महत्त्वपूर्ण छ।प्रतिक्रिया बफरमा अन्य पदार्थहरू, मेसिनहरू र प्रोटोकलहरू हटाउनुहोस्।प्राइमरको गुणस्तरले पनि qRT-PCR को प्रवर्द्धन दक्षतामा ठूलो प्रभाव पार्छ।नतिजाहरूको शुद्धता सुनिश्चित गर्नको लागि, दुबै सापेक्ष प्रतिदीप्ति परिमाणीकरण र पूर्ण प्रतिदीप्ति परिमाणीकरणले प्राइमरहरूको प्रवर्धन दक्षता पत्ता लगाउन आवश्यक छ।यो मान्यता छ कि प्रभावकारी qRT-PCR प्रवर्धन दक्षता 85% र 115% को बीचमा छ।त्यहाँ दुई तरिकाहरू छन्:
1. मानक वक्र विधि:
acDNA मिलाउनुहोस्
bग्रेडियन्ट कमजोरी
c.qPCR
dप्रवर्धन दक्षता गणना गर्न रैखिक प्रतिगमन समीकरण
2. LinRegPCR
LinRegPCR वास्तविक समय RT-PCR डेटाको विश्लेषणको लागि एउटा कार्यक्रम हो, जसलाई SYBR ग्रीन वा समान रसायनमा आधारित मात्रात्मक PCR (qPCR) डेटा पनि भनिन्छ।कार्यक्रमले गैर-आधार रेखा सुधार गरिएको डेटा प्रयोग गर्दछ, प्रत्येक नमूनामा आधारभूत सुधार अलग-अलग गर्दछ, विन्डो-अफ-लाइनरिटी निर्धारण गर्दछ र त्यसपछि PCR डेटा सेट मार्फत सीधा रेखा फिट गर्न रैखिक प्रतिगमन विश्लेषण प्रयोग गर्दछ।यस रेखाको ढलानबाट प्रत्येक व्यक्तिगत नमूनाको पीसीआर दक्षता गणना गरिन्छ।औसत PCR दक्षता प्रति एम्प्लिकन र प्रति नमूना Ct मान प्रति नमूना प्रारम्भिक एकाग्रता गणना गर्न प्रयोग गरिन्छ, मनमानी फ्लोरोसेन्स एकाइहरूमा व्यक्त गरिन्छ।डाटा इनपुट र आउटपुट एक्सेल स्प्रेडसिट मार्फत हुन्छ।नमूना मात्र
मिश्रण आवश्यक छ, कुनै ढाँचा छैन
चरणहरू आवश्यक छन्:(बोले CFX96 लाई उदाहरणको रूपमा लिनुहोस्, स्पष्ट ABI भएको मेसिन होइन)
परिक्षण:यो एक मानक qPCR प्रयोग हो।
qPCR डाटा आउटपुट:LinRegPCR ले आउटपुट फाइलहरूको दुई रूपहरू पहिचान गर्न सक्छ: RDML वा क्वान्टिफिकेशन प्रवर्द्धन परिणाम।वास्तवमा, यो मेशिन द्वारा चक्र नम्बर र प्रतिदीप्ति संकेत को वास्तविक समय पत्ता लगाउने मान हो, र एम्प्लीफिकेशन रैखिक खण्ड दक्षता को प्रतिदीप्ति परिवर्तन मूल्य विश्लेषण गरेर प्राप्त गरिन्छ।
डाटा चयन: सिद्धान्तमा, RDML मान प्रयोगयोग्य हुनुपर्छ।यो अनुमान गरिएको छ कि मेरो कम्प्युटरको समस्या यो हो कि सफ्टवेयरले RDML पहिचान गर्न सक्दैन, त्यसैले मसँग एक्सेल आउटपुट मान मूल डाटाको रूपमा छ।पहिले डेटाको कुनै नराम्रो स्क्रिनिङ गर्न सिफारिस गरिन्छ, जस्तै नमूनाहरू थप्न असफल, आदि। अंकहरू आउटपुट डेटामा मेटाउन सकिन्छ (अवश्य पनि, तपाईंले तिनीहरूलाई मेटाउन सक्नुहुन्न, LinRegPCR ले पछिको चरणमा यी बिन्दुहरूलाई बेवास्ता गर्नेछ)।
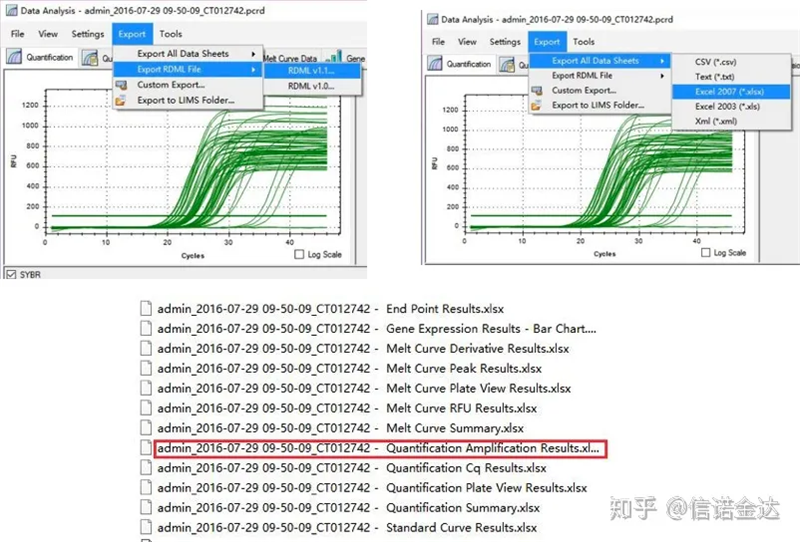
Fig5 qPCR डाटा निर्यात
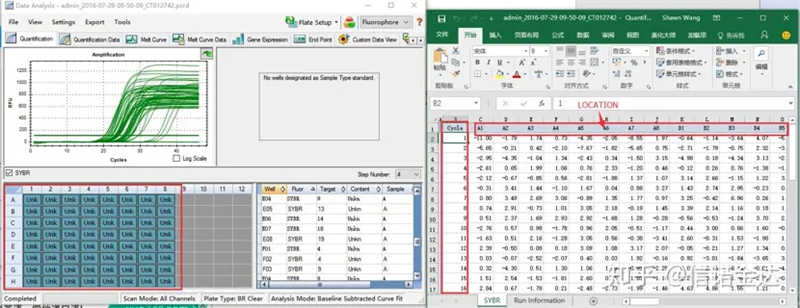
Fig6 उम्मेदवार नमूनाहरूको चयन
डाटा इनपुट:योग्यता प्रवर्द्धन परिणामहरू खोल्नुहोस्।
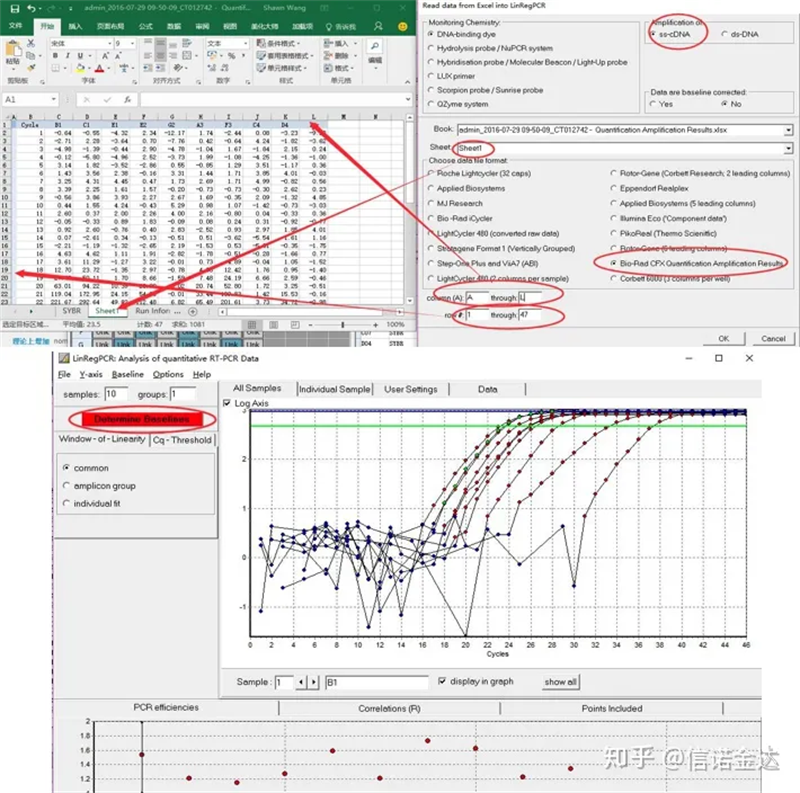
linRegPCR डाटा इनपुटको चित्र 7 चरणहरू
नतिजा:यदि कुनै पुनरावृत्ति छैन भने, कुनै समूह आवश्यक छैन।यदि त्यहाँ पुनरावृत्ति छ भने, समूह नमूना समूहमा सम्पादन गर्न सकिन्छ, र जीनको नाम पहिचानकर्तामा प्रविष्ट गरिन्छ, र त्यसपछि उही जीन स्वचालित रूपमा समूहबद्ध हुनेछ।अन्तमा, फाइलमा क्लिक गर्नुहोस्, एक्सेल निर्यात गर्नुहोस्, र परिणामहरू हेर्नुहोस्।प्रत्येक इनारको प्रवर्धन दक्षता र R2 परिणामहरू प्रदर्शन गरिनेछ।दोस्रो, यदि तपाईंले समूहहरूमा विभाजन गर्नुभयो भने, सुधार गरिएको औसत प्रवर्धन दक्षता प्रदर्शित हुनेछ।सुनिश्चित गर्नुहोस् कि प्रत्येक प्राइमरको प्रवर्धन दक्षता 85% र 115% को बीचमा छ।यदि यो धेरै ठूलो वा धेरै सानो छ भने, यसको मतलब प्राइमरको एम्प्लीफिकेशन दक्षता कमजोर छ।
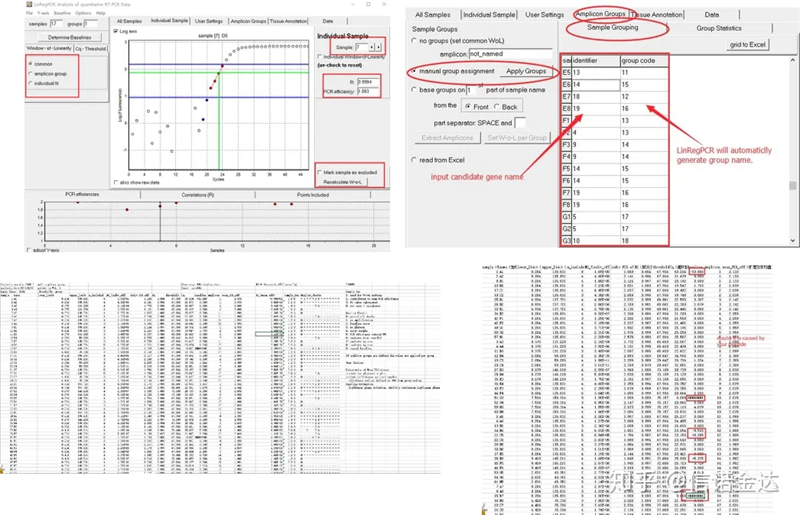
चित्र 8 नतिजा र डाटा आउटपुट
प्रयोगात्मक प्रक्रिया:
आरएनए गुणस्तर आवश्यकताहरू:
शुद्धता:१.७2.0 ले संकेत गर्दछ कि त्यहाँ अवशिष्ट आइसोथियोसाइनेट हुन सक्छ।क्लीन न्यूक्लिक एसिड A260/A230 लगभग 2 हुनुपर्छ।यदि त्यहाँ 230 nm मा बलियो अवशोषण छ भने, यसले फेनेट आयनहरू जस्ता जैविक यौगिकहरू छन् भनेर संकेत गर्दछ।थप रूपमा, यो 1.5% agarose जेल इलेक्ट्रोफोरेसिस द्वारा पत्ता लगाउन सकिन्छ।मार्करलाई देखाउनुहोस्, किनकि ssRNA सँग कुनै विकृतीकरण छैन र आणविक वजन लोगारिदमसँग रैखिक सम्बन्ध छैन, र आणविक वजन सही रूपमा व्यक्त गर्न सकिँदैन।एकाग्रता: सैद्धान्तिक रूपमाहोइन100ng/ul भन्दा कम, यदि एकाग्रता धेरै कम छ भने, शुद्धता सामान्यतया कम छ अग्लो छैन
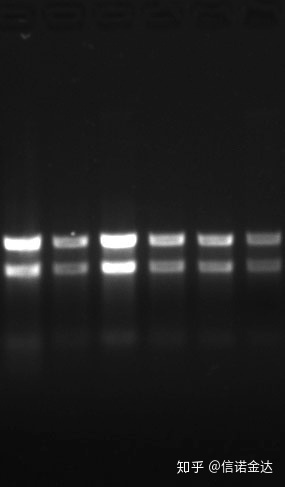
Fig9 RNA जेल
थप रूपमा, यदि नमूना बहुमूल्य छ र RNA एकाग्रता उच्च छ भने, यसलाई निकासी पछि aliquot गर्न सिफारिस गरिन्छ, र RNA लाई रिभर्स ट्रान्सक्रिप्शनको लागि 100-300ng/ul को अन्तिम एकाग्रतामा पातलो पार्नुहोस्।माउल्टो ट्रान्सक्रिप्शन को प्रक्रिया, जब mRNA ट्रान्सक्रिप्शन गरिन्छ, ओलिगो (dt) प्राइमरहरू जुन विशेष रूपमा polyA टेलहरूमा बाँध्न सकिन्छ रिभर्स ट्रान्सक्रिप्शनको लागि प्रयोग गरिन्छ, जबकि lncRNA र circRNA ले कुल RNA को रिभर्स ट्रान्सक्रिप्शनको लागि अनियमित हेक्सामर (Random 6 mer) प्राइमरहरू प्रयोग गर्दछ miRNA को लागि, miRNA-विशिष्ट ट्र्याक्रिप्शनका लागि प्राइमरहरू प्रयोग गरिन्छ।धेरै कम्पनीहरूले अब विशेष टेलिङ किटहरू लन्च गरेका छन्।स्टेम-लूप विधिको लागि, टेलिङ विधि अधिक सुविधाजनक, उच्च-थ्रुपुट, र अभिकर्मक-बचत हो, तर एउटै परिवारका miRNAs छुट्याउनको प्रभाव स्टेम-लूप विधि जत्तिकै राम्रो हुनु हुँदैन।प्रत्येक रिभर्स ट्रान्सक्रिप्शन किटमा जीन-विशिष्ट प्राइमरहरू (स्टेम-लूपहरू) को एकाग्रताका लागि आवश्यकताहरू हुन्छन्।miRNA को लागि प्रयोग गरिएको आन्तरिक सन्दर्भ U6 हो।स्टेम-लूप इन्भर्सनको प्रक्रियामा, U6 को ट्यूबलाई अलग-अलग उल्टो गर्नुपर्छ, र U6 को अगाडि र पछाडि प्राइमरहरू सीधै थपिनुपर्छ।दुबै circRNA र lncRNA ले HKGs लाई आन्तरिक सन्दर्भको रूपमा प्रयोग गर्न सक्छ।माcDNA पत्ता लगाउने,
यदि RNA मा कुनै समस्या छैन भने, cDNA पनि ठीक हुनुपर्छ।यद्यपि, यदि प्रयोगको पूर्णता पछ्याइएको छ भने, आन्तरिक सन्दर्भ जीन (सन्दर्भ जीन, आरजी) प्रयोग गर्नु राम्रो हुन्छ जसले सीडीएसबाट जीडीएनए छुट्याउन सक्छ।सामान्यतया, आरजी एक गृहकार्य जीन हो।, HKG) चित्र 10 मा देखाइएको छ;त्यसबेला, मैले सोयाबीन भण्डारण प्रोटिन बनाउँदै थिएँ, र आन्तरिक सन्दर्भको रूपमा इन्ट्रोन्स भएको actin7 प्रयोग गर्थे।gDNA मा यस प्राइमरको एम्प्लीफाइड टुक्राको आकार 452bp थियो, र यदि cDNA टेम्प्लेटको रूपमा प्रयोग गरिएको थियो भने, यो 142bp थियो।त्यसपछि परीक्षणको नतिजाले cDNA को भाग वास्तवमा gDNA द्वारा दूषित भएको पत्ता लगायो, र यसले यो पनि प्रमाणित गर्यो कि रिभर्स ट्रान्सक्रिप्शनको नतिजामा कुनै समस्या थिएन, र यसलाई PCR को टेम्प्लेटको रूपमा प्रयोग गर्न सकिन्छ।सीडीएनएसँग सिधै एगारोज जेल इलेक्ट्रोफोरेसिस चलाउनु बेकार छ, र यो एक फैलिएको ब्यान्ड हो, जुन विश्वस्त छैन।
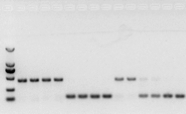
चित्र 10 cDNA पत्ता लगाउने
QPCR सर्तहरूको निर्धारणसामान्यतया किटको प्रोटोकल अनुसार कुनै समस्या छैन, मुख्यतया tm मानको चरणमा।यदि प्राइमर डिजाइन गर्दा केही प्राइमरहरू राम्ररी डिजाइन गरिएका छैनन् भने, tm मान र सैद्धान्तिक 60°C बीचको ठूलो भिन्नताको परिणामस्वरूप, यो सिफारिस गरिन्छ कि cDNA नमूनाहरू मिलिसकेपछि, प्राइमरहरूसँग ग्रेडियन्ट PCR चलाउनुहोस्, र TM मानको रूपमा ब्यान्ड बिना तापक्रम सेट गर्नबाट बच्न प्रयास गर्नुहोस्।
डाटा विश्लेषण
परम्परागत सापेक्ष प्रतिदीप्ति मात्रात्मक PCR प्रशोधन विधि मूलतः 2 अनुसार हो-ΔΔCT।डाटा प्रशोधन टेम्प्लेट।
सम्बन्धित उत्पादनहरु:
वास्तविक समय पीसीआर सजिलोTM - ताकमान
वास्तविक समय पीसीआर सजिलोTM - साइबर ग्रीन आई
RT Easy I (पहिलो स्ट्र्यान्ड cDNA संश्लेषणको लागि मास्टर प्रिमिक्स)
RT Easy II (qPCR को लागि पहिलो स्ट्र्यान्ड cDNA संश्लेषणको लागि मास्टर प्रिमिक्स)
पोस्ट समय: मार्च-14-2023



